How AI and language models can change the energy industry
In this article we will share our thoughts around large language models and the exciting developments in AI, and give examples of how this technology can be used by energy professionals.
Conferences are fantastic places to hear about advances in your field of interest, networking, and to have the chance of communicating work or ideas you are proud of. At the end of March, I was lucky enough to attend the DIGEX conference in Oslo, which is a conference for geoscientists, data scientists, and digitalization professionals to present and discuss new tools and applications that aid digitalization, better decision making, and better cross disciplinary understanding in the subsurface domain. The biggest new trend at this year’s conference was the use of conversational artificial intelligence (AI) and large language models (LLM).
In addition to several presentations on the subject, there was also a dedicated panel discussion consisting of industry experts to talk about the uses, risks, and future of LLM in the energy industry. We felt inspired by the discussion panel and wanted to share our thoughts around large language models and the exciting developments in AI. We also give a few examples of how this technology can be used by energy professionals.
Artificial Intelligence
AI is the simulation of human intelligence or cognitive processes by machines or computer systems. We are familiar with technology that uses AI such as search engines, recommendation systems in social media and streaming services, self-driving cars, or human speech understanding (virtual assistants like Siri and Alexa). In fact, most of us will interact with multiple applications or products that use AI every single day. Until recently, most of our interactions with AI have been passive, with AI hidden as the back-end drivers of software or smart products.
In 2023, it very much feels like we are going through a major shift, or perhaps more of a giant leap forward AI. AI has become more visible, more accessible, and at the forefront of the tools we are using.
Technology and science experience times of explosive innovation often referred to as a paradigm shift, where, after a period of stability or stagnation, new ideas break through and forever and irreversibly change the landscape of a given field. In 2023, it very much feels like we are going through a major shift, or perhaps more of a giant leap forward AI. AI has become more visible, more accessible, and at the forefront of the tools we are using. We are now conscious users that actively and intentionally interact with AI services. This new era of AI and this is being powered in part by the arrival of large language models like ChatGPT (OpenAI), LLaMa (Meta), and PaLM (Google). Even from the first interaction, it is clear that conversational AI technologies are both extremely powerful and very easy to use.
Language Models
One of the main applications of AI is to replicate human language abilities in communication, understanding, and reasoning. In their simplest forms, language models aim to predict the next word or missing word within a sequence of other words or “tokens”. These types of models are familiar in situations such as predictive text.
Taking this one stage further, more complex models using neural networks, can predict or generate longer sentences or pieces of text. Examples of these include chatbots or simple text generators that rely on the concept of pre-training and fine tuning of models to specific data. The main drawback of these models, is that they take effort to train, collect relevant data, and they are often highly specialized to a single or very limited set of tasks. Secondly, due to their sequential network architecture, simpler language models struggle to adjust the importance of different words within a body of text because the window of context of the input data is fixed during training. These types of models find it difficult to learn complex language patterns and lack flexibility to adapt to different user inputs.
Whilst language models are widely used, they have not made the same level of impact of the energy industry compared to machine learning, image classification, or robotics and automation.
Large Language Models
LLM are a new class of language models that have a specific set of characteristics. The key features of LLM are:
Size: LLM are much larger, with billions of parameters (175 billion for GPT-3) compared to other language models (typically millions to a few billion parameters – see table). Due to their massive size, LLM require their own specialized hardware and software tools to support training and deployment.
Network architecture: LLMs use new advances in neural network architectures (namely transformers and attention), which enable the model to consider the global context of larger batches of input text and understand more complex linguistic patterns. They are also to differentiate and correctly weigh different parts of the input sequence of words allowing them to adapt to different tasks and identify the key pieces of information.
LLMs have better memory management than earlier models, meaning that information can be stored and retrieved from longer input sequences of text. Improvements in context awareness helps form more coherent and appropriate responses to user inputs (or ‘prompts’).
Pre-training: LLM are pre-trained on huge amounts of unlabeled data using unsupervised learning techniques. These training methods allow LLM to learn a wider range of linguistic patterns and structures to make them able to solve complex and varied tasks. LLMs can also be ‘multimodal’ and solve both text and image related problems (e.g., GPT-4).
It is these characteristics that give LLM their powerful range of language skills. With an increased capacity to store and learn information, LLMs are significantly better at understanding nuances and performing logical reasoning than their predecessors. LLM understand more complex patterns in language and can therefore utilize prior knowledge more effectively to produce realistic and natural sounding text.
Lastly, LLM are commonly deployed inside an easy-to-use conversational interface. This natural method of communicating through a series prompts and responses feels much like you are talking to a human or an expert. It is this ease of use that means anybody, without requiring any knowledge of the underlying AI, can use the technology effectively without prior training.
|
Model |
Company |
Open source |
Release Date |
Parameters (in billions) |
Training Data |
|
GPT-3 |
OpenAI |
No |
June 2020 |
175 |
Webpages |
|
AlphaCode |
DeepMind |
No |
February 2022 |
0.3-41 |
Code |
|
Chinchilla |
DeepMind |
No |
March 2022 |
70 |
Webpages / Books |
|
PaLM |
|
No |
April 2022 |
62-540 |
Conversation Data |
|
LLaMa |
Meta |
Yes |
February 2023 |
7-65 |
Webpages |
|
GPT-4 |
OpenAI |
No |
March 2023 |
170,000 |
Webpages |
|
Galactica |
Meta |
Yes |
November 2022 |
120 |
Scientific Data |
Table data collected from Zhao et al (2023). A Survey of Large Language Models. Training Data lists the dominant data types (>40%) used for training the model.
Uses
Personal productivity
ChatGPT and other LLM are primarily seen as productivity tools, and their ability to create content opens many bottlenecks in productivity and creativity. Time consuming writing tasks that require searching, reading, writing, and editing text can be quickly lifted onto or assisted by, for example, ChatGPT. In this way LLMs, effectively consolidate the internet by keeping the user within one simple interface and removes the need to jump from different sites and tabs. Similarly, the ability of LLM to summarize large portions of the internet makes them highly effective as learning tool for users who are interested in a new or unfamiliar topic. LLMs can also solve programming tasks and understand patterns in code. For developers, they can help to quickly generate working code, can translate between different programming languages, or explain concepts that the user has not used before.
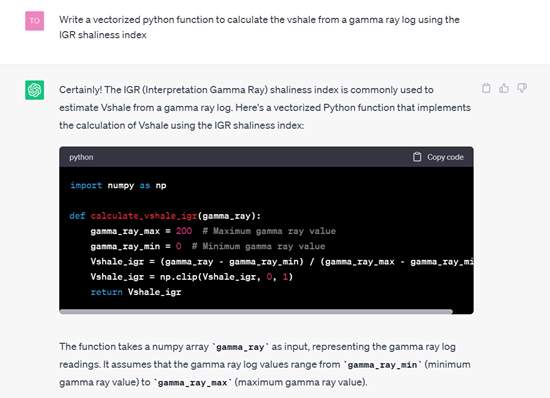
In the example below, we take a very simple petrophysical workflow of calculating the vshale from a gamma ray log. We first ask ChatGPT how to calculate vshale and what its significance is for reservoir characterization is. We follow up by asking it to create a useable python function to calculate vshale from a gamma ray log. In this simple task, ChatGPT does a sufficient job. We get a good description of vshale and a simple piece of code that works.

Vendor supplied tools
More and more vendors are incorporating language models and AI directly into their software to enhance user experience or productivity. Examples include the addition of ChatGPT to Microsoft office, Adobe Firefly, or Copilot in Github. These kinds of solutions will become more ubiquitous and place AI in the hands of an even wider audience. Users will be able to stay in their software of choice that they are comfortable with and enjoy any additional productivity gains. It is highly likely that we will begin to see in-application based assistants in subsurface application that can help the user navigate the documentation. AI assistance could also be used to suggest alternative workflows, algorithms, or analysis of the data the user is working with, which may be particularly useful for inexperienced interpreters or users who are new to the software.
More and more vendors are incorporating language models and AI directly into their software to enhance user experience or productivity.
Vendors may also offer more specialized tools for targeted or transformative changes to certain workflows. The translation of individual business cases into workflows that can be handled by AI can be complex but may carry significant productivity or qualitative. Open-source libraries, like Langchain, offer the building blocks for constructing workflow driven tools and open the floodgates for bespoke solutions. Take for example, a custom tool that can be pointed to a directory or file(s) from the companies own internal data and the user can then quickly and easily explore the information contained in those files through a series of prompts and responses. For example, a data manager or geoscientist would be able to scan many drill reports quickly and effectively, and the language model would retrieve and summarize relevant information to the users’ prompt. Document scanning using AI would both save significant time and could improve the quality of the process.
Current risks and limitations
Due to the pace at which this technology is evolving the risks and limitations associated with LLMs are dynamically changing.
All LLM are known to make mistakes or in some cases provide false or misleading responses. When this occurs, the responses are referred to as ‘Hallucinations’. The developers of GPT-4 make it clear that users of LLM should take great care when using model outputs, especially in ‘high-stakes contexts’. Protocols such as ‘human reviews, grounding with additional context or avoiding high-stakes cases’ are a few of the suggestions made in OpenAI’s GPT-4 technical report for reducing risks associated with hallucinations. Enrergy professionals accustomed to the environmental and financial risks associated with decision making processes in the industry. LLM would be mostly used for faster information retrieval and in theory could provide decision makers with both more data and more time to make their decisions.
There are many concerns around privacy and security around LLM usage. Conversations can be long, detailed, personal, or contain confidential data. For example, engineers at Samsung were using ChatGPT to improve the software in one of their products but ended up leaking source code and meeting notes that were subsequently incorporated into the training data of ChatGPT.
It must be stressed that many LLMs are intended to be generalized tools, for wider public use. Models may struggle on very specific knowledge or information that was not included in its training data. For example, GPT-4 lacks knowledge of events past the training data cutoff of September 2021 (OpenAI GPT-4 technical report). Users and developers of tools which use LLMs must bear this in mind and should consider using appropriate models for the task that they are working on. For example, using LLM trained on code (CoPilot or AlphaCode) or scientific data (Galactica) rather than webpages, might give much better results than a more generalist model like GPT-4.
In the energy industry, domain experts often work with a combination of text, numerical, math or physical equations, images, diagrams, and maps. LLM are improving quickly in these tasks, and when they do become sufficiently performant across a wider set data types and tasks, they will be much more powerful and useful in subsurface workflows.
In fact, many of the limitations of LLMs can be avoided by using more advanced prompting techniques. For complex workflow related tasks, better results can be achieved through combining (‘chaining’) multiple language modes or even adding image or video models that work together to solve separate subtasks or to more find consistent answers.
Back-and-forth feedback within companies should be encouraged to educate people about capabilities, prompt engineering and any discovered opportunities for greater workflow improvements that may mitigate many of these kinds of limitations.
Cegal and AI
Cegal sees huge potential in the AI market are currently exploring the use of AI in all the major branches of the company. As a global tech powerhouse, Cegal can enable our clients to leverage AI capabilities safely and ethically on their corporate data and systems, to optimize business processes, enhance customer experience, and create new revenue streams. Cegal is currently exploring ways of improving technical support and customer user experiences for our products with AI that utilizes our own internal data. We are also embracing responsible personal use of AI such as ChatGPT and CoPilot for productivity and exploring new ideas.
Sources:
GPT-4 Technical Report, OpenAI, March 2023
Zhao, W.X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z. and Du, Y., 2023. A Survey of Large Language Models. arXiv preprint arXiv:2303.18223.
ChatGPT was used for discovering general background information on LLM. All responses were rewritten in our own words, and nothing was copy and pasted into the article.
DIGEX conference panel discussion points were supplemented with our viewpoints.